
Big (open) data in sports
A missed opportunity for teams and organisations?

BIG Data.
It’s an overused, yet somewhat ill-defined phrase.
In a domain where progress occurs at a literally exponential scale, a definition using a relative reference (“big”) is bound to be confusing, if not meaningless.
But there does exist some general guides and descriptions which can help us out. According to Oracle, data can be big in many ways. It can be voluminous, generated at a high velocity or include a high variety. They also describe big data as being “so voluminous that traditional data processing software just can’t manage them”. While not particularly precise, it does help us to get the vibe of the thing.

Big data has been on my mind over the last couple of months. The reason being that I spent the time on a project building data analysis apps for visualising and exploring very large datasets.
The Apps
Here’s an example based on ship data from around the United States:
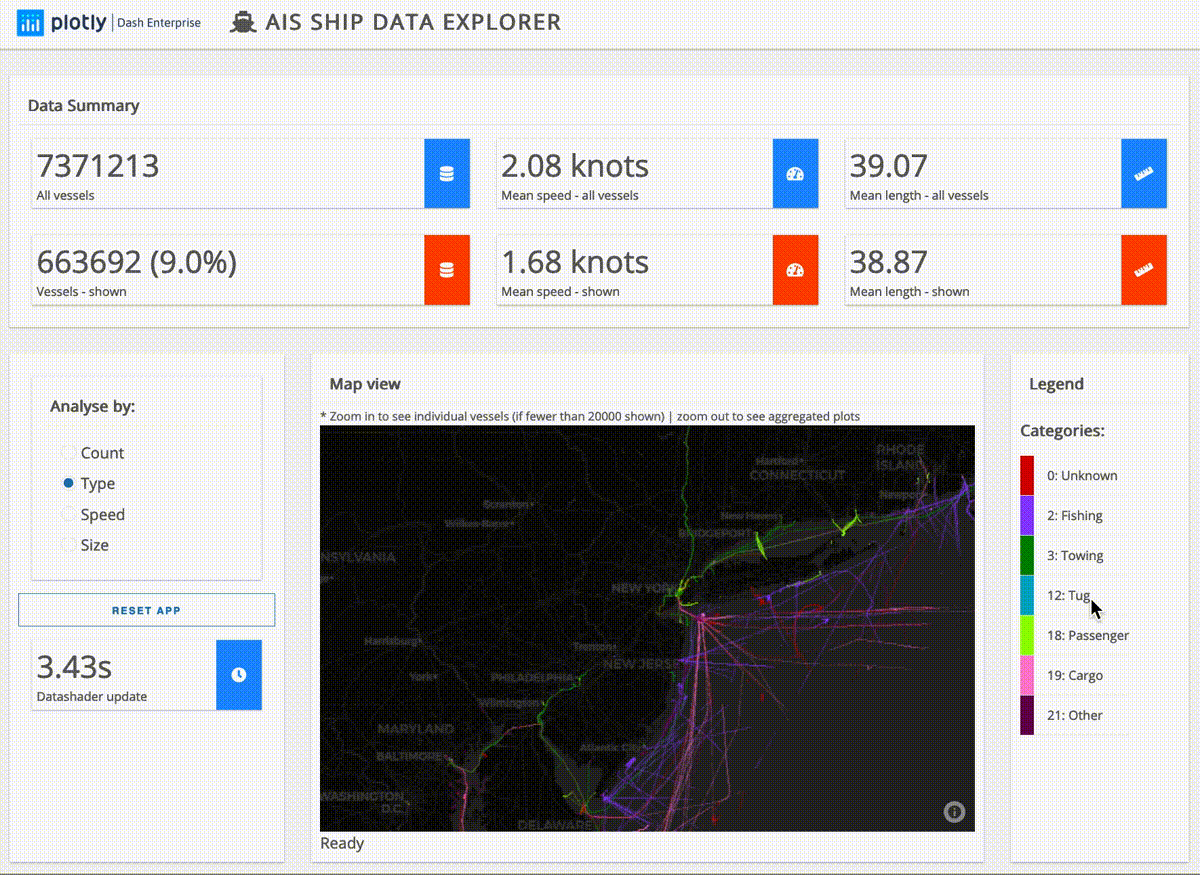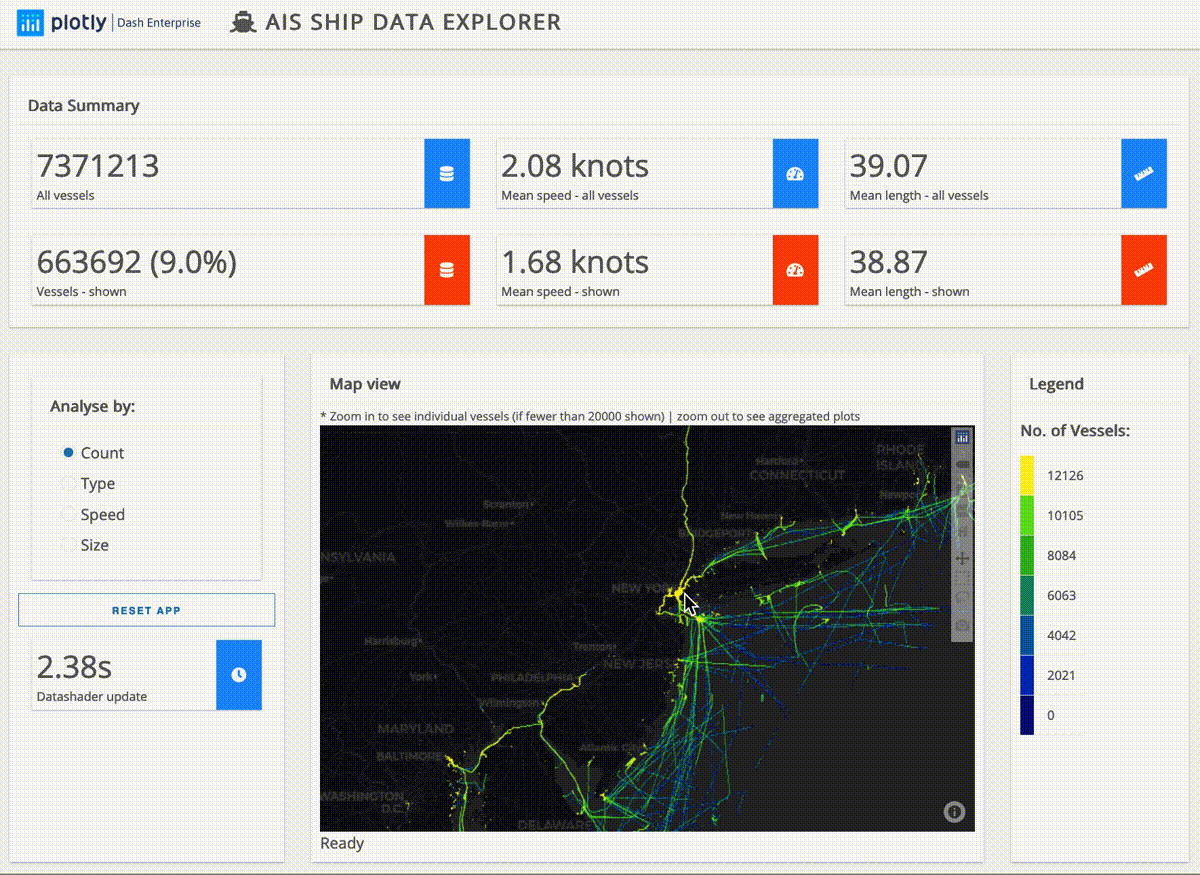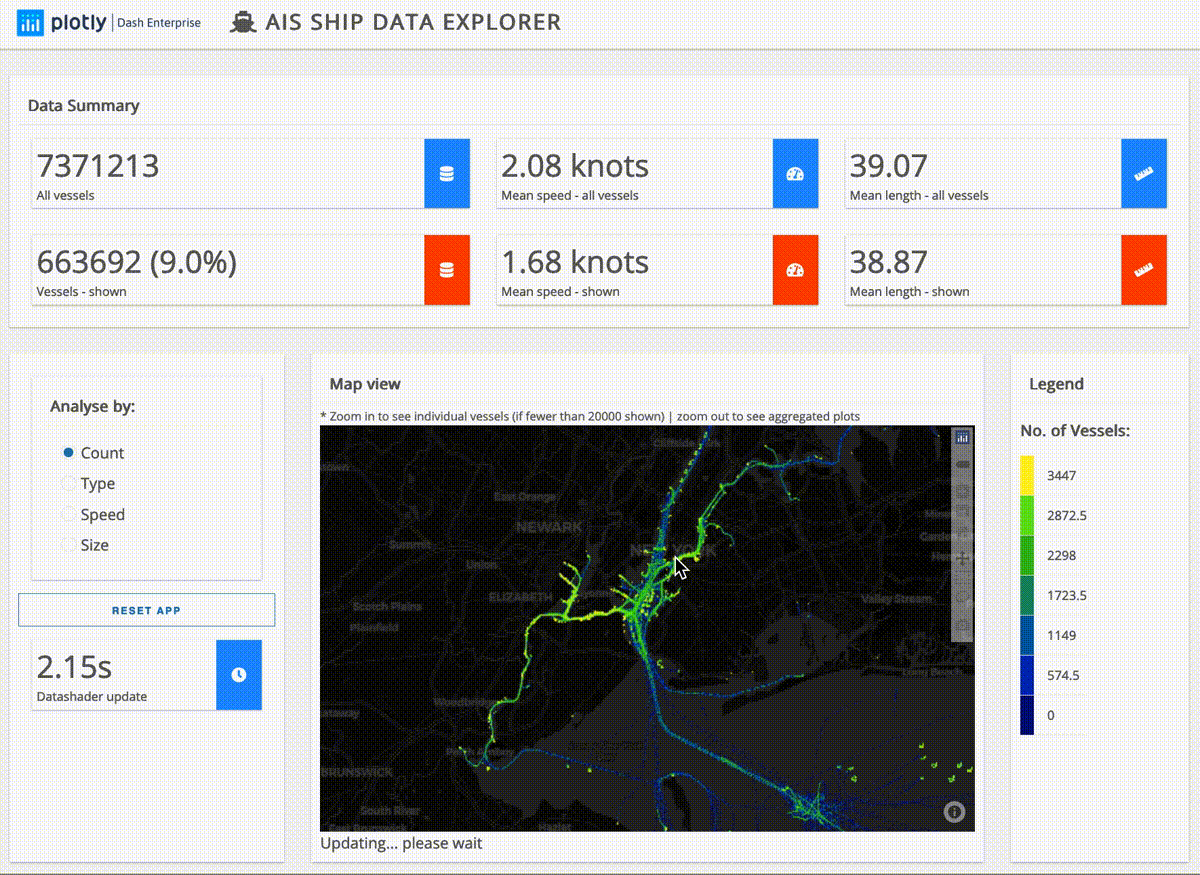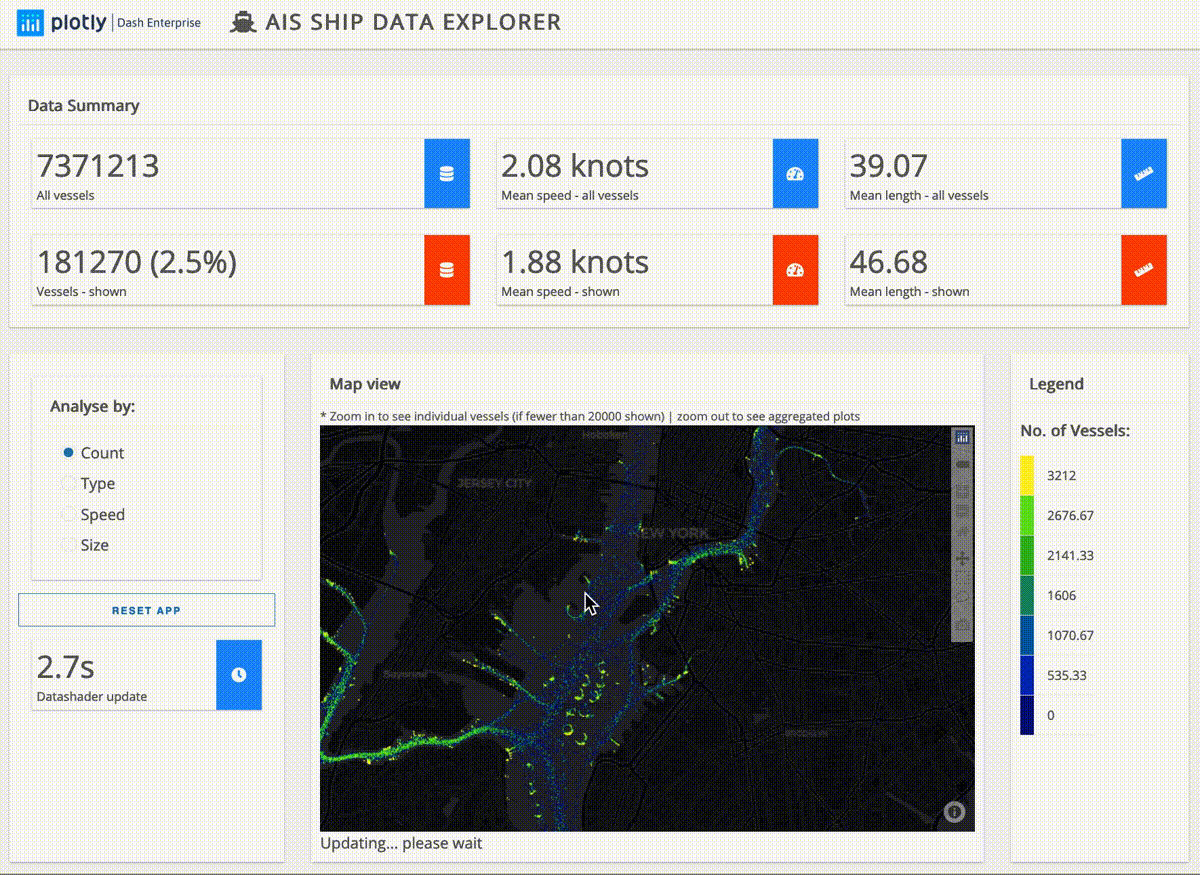
And this next app lays out for analysis the U.S. power grid as well as its wind and solar power plants:
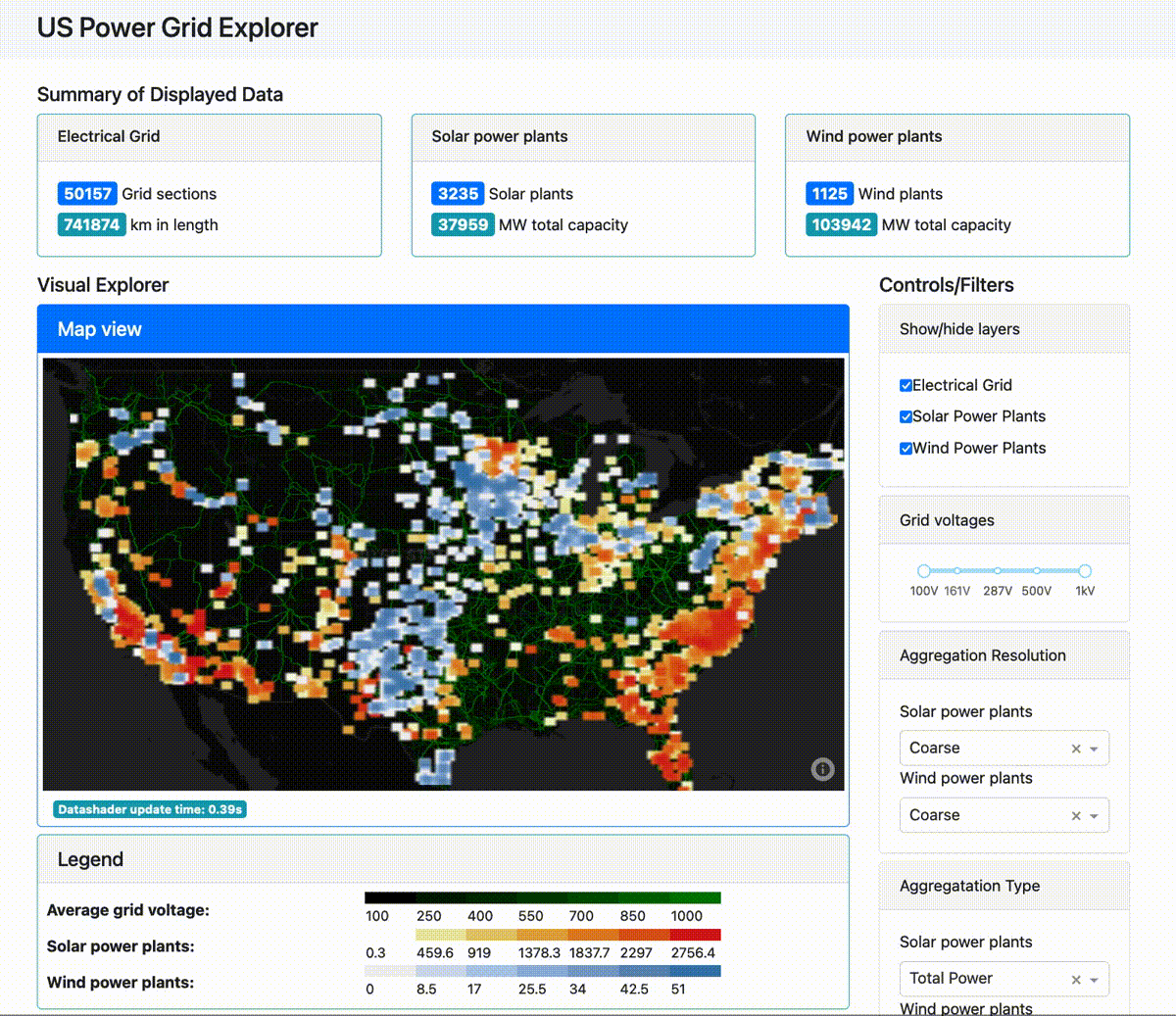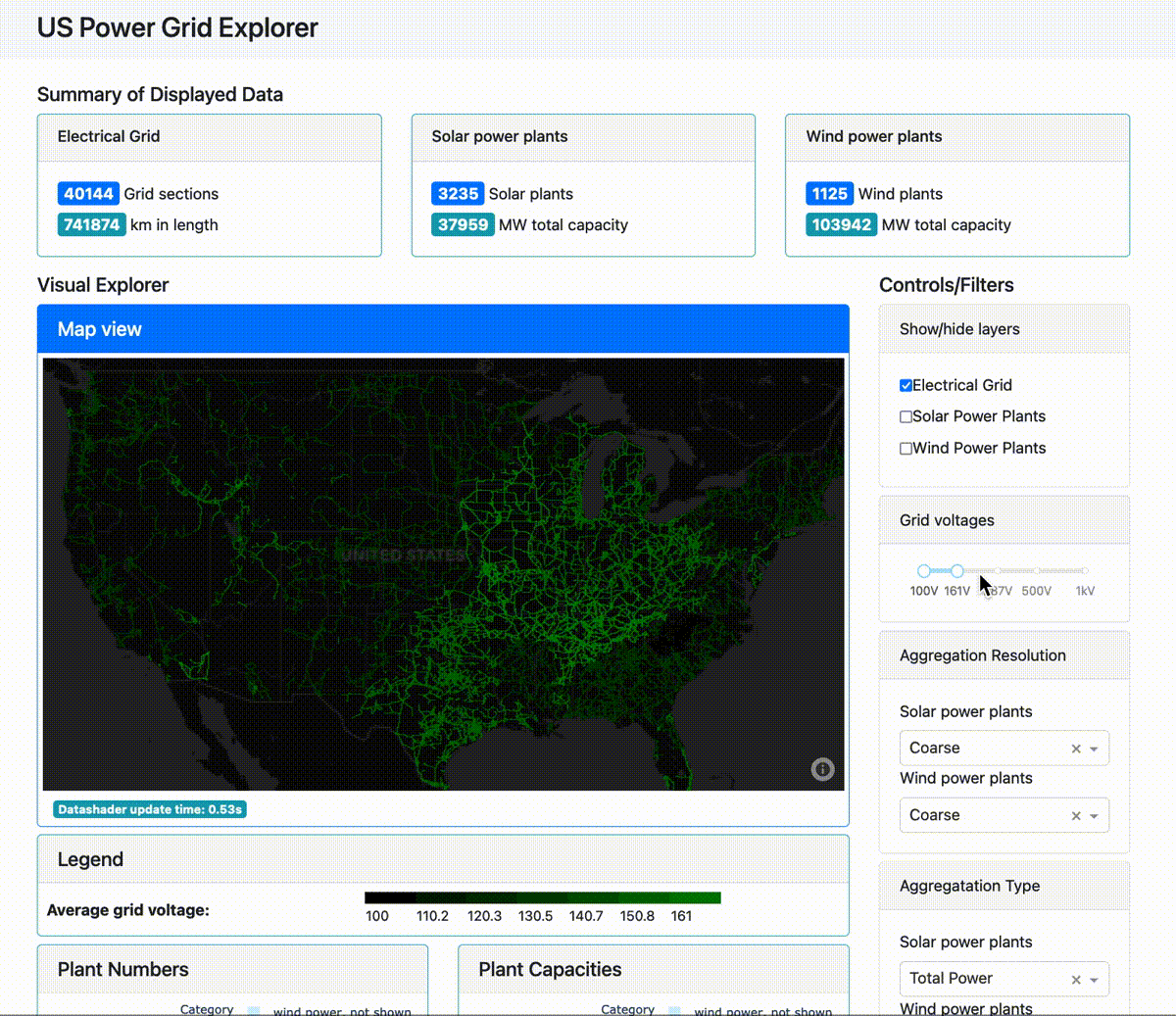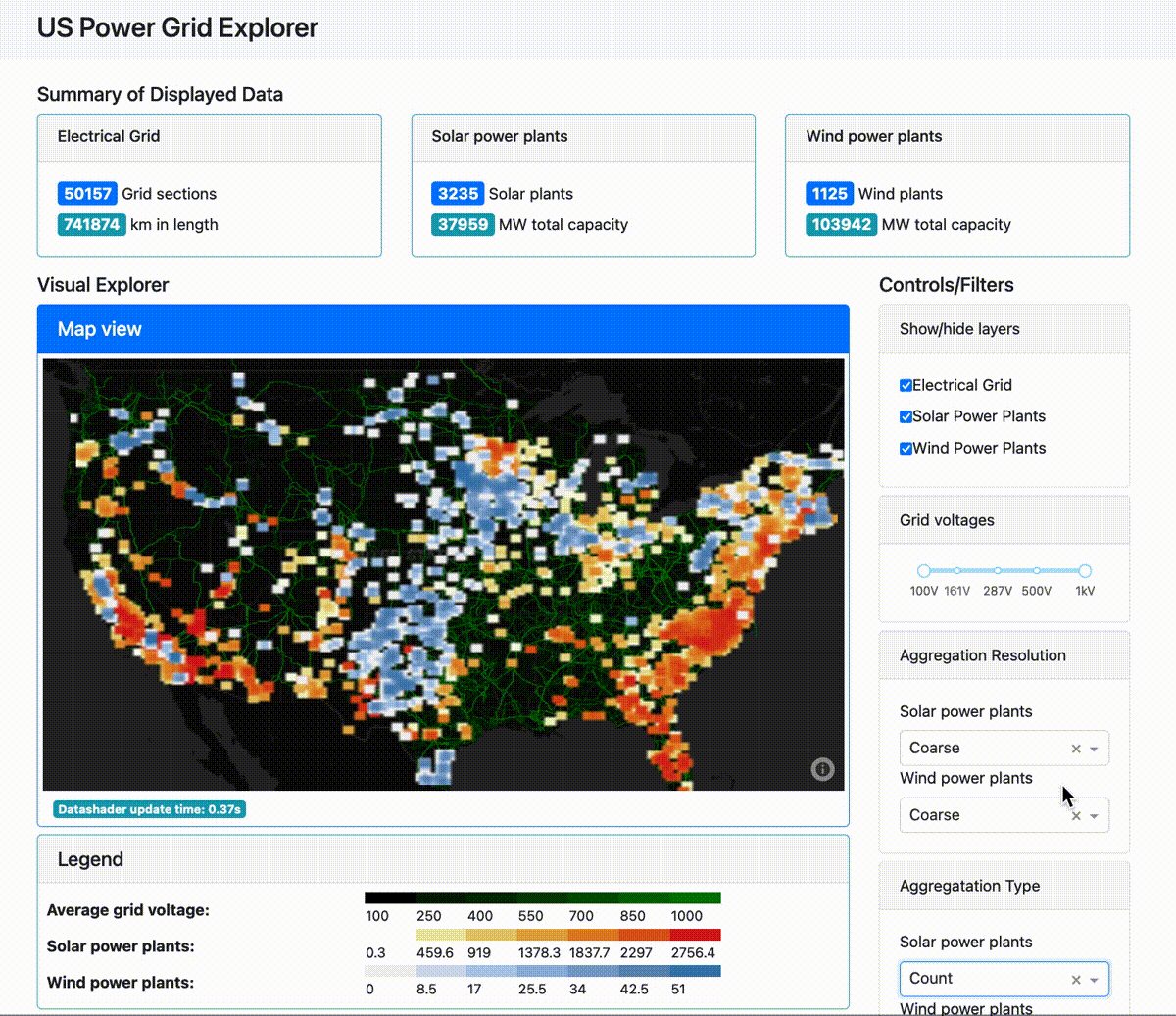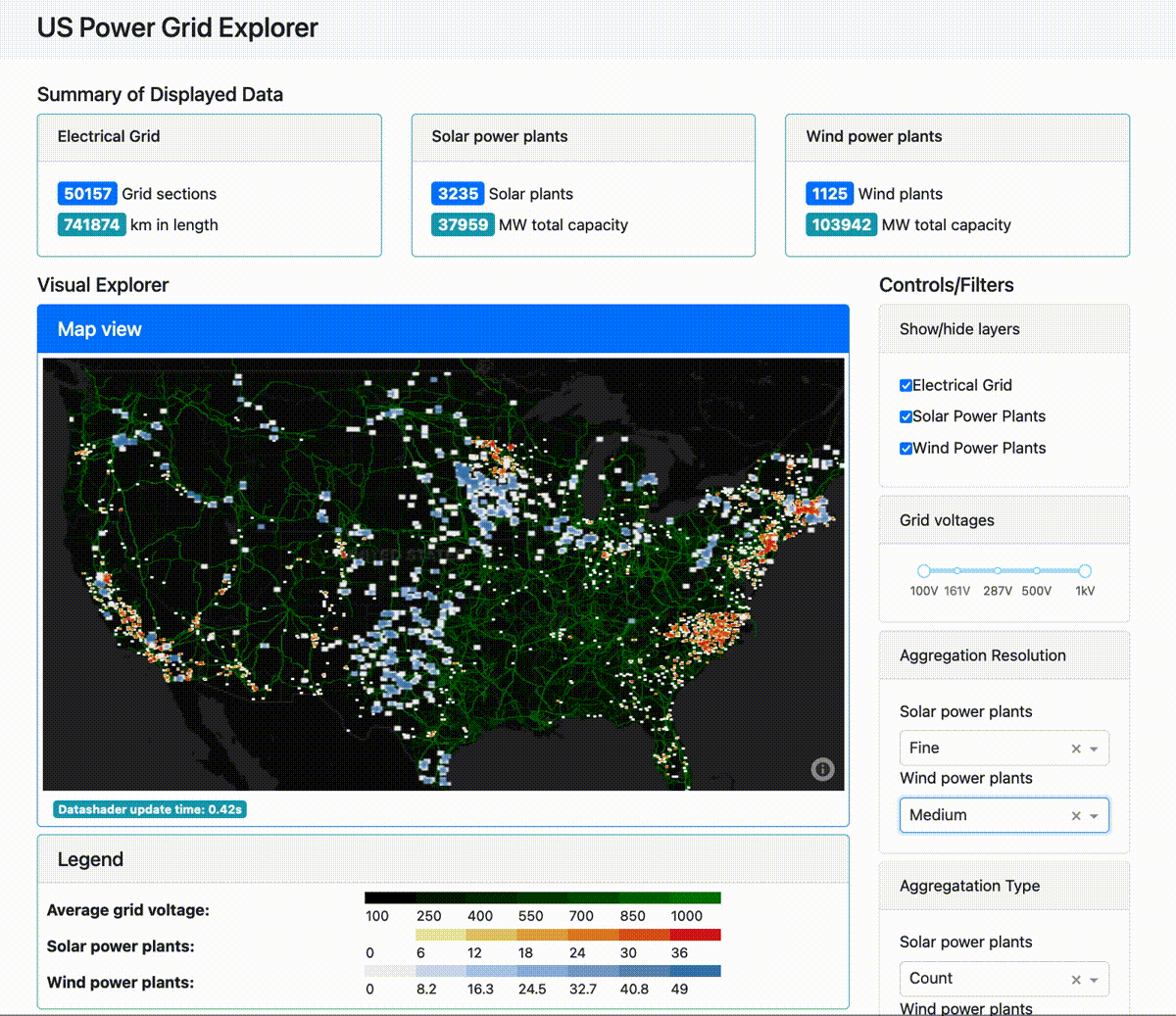
(For those interested, the tech stack here is Plotly Dash for the front end, Dask for distributed computing on the back end, with an optional Coiled remote compute cluster. You can find the source code for the power grid app here.)
The ship data explorer above is processing just under ten millon rows of data in seconds. To process larger data the app simply needs to be slightly modified to connect to a larger cluster.
Cool, right? And I was able to build these with nothing but open source tools.
Data, data everywhere
In many cases, open-source data science tools are superior to any closed-source tools. Compute power is readily availble to almost anyone with moderate means through startups like Coiled or traditional giants. Lastly, huge, detailed, informative datasets like this and many others are freely and publicly available.
Both Amazon (here) and Google (here) each already make hundreds of large, sophiscated datasets available at no cost.
Want to understand the global air quality patterns? OpenAQ can help you out. Is a traffic model of NYC of interest to you? You can get every trip record of New York cabs here. There are any number of medical datasets like brain scans, X-Rays, or even DNA sequences. If you’re interested in liquor consumption in Iowa, this dataset shows every wholesale purchase made in the state since 2012.
Big data, while seemingly intimidating, is far from inaccessible - except, seemingly, in sports.
And that’s a huge shame, as well as a missed opportunity for many organisations.
(Lack of) Big OPEN data in sports
Sure, we have more data in sports than ever. But it’s been mostly summary or aggregate statistics like player or team ratings, or how well a team does in certain situations. But data such as this is limited - it’s already been collected and evaluated in certain ways.
In terms of raw, granular, data from which we might draw our own conclusions, there isn’t much available save but a few exceptions. And even those are often severely limited.
The MLB makes their STATCAST data available, which includes detailed information like where exactly the pitcher releases the ball, how fast it was and how much it spins / moves, and how hard the ball is hit by the batter and the launch angle. It’s improved our understanding of baseball immensely.


But the StatCast data is only just a small sample of available data, not to mention that the game is more than just the ball.
The NBA / SportsVU made its tracking data available containing over 90+GBs(!) of player and ball positions throughout games. People have done some extraordinary things with it, like for instance this which is a part of Christopher Jenness’ work quantifying spacing in defense.

Unfortuantely the only available data is from the 2015-2016 season, unable to provide historical context not to mentioned now being outdated.
In soccer, only a smattering of player tracking data from just a few historical matches is available via data service providers.
All of this is a little disappointing and precisely why this is a huge opportunity for many.
We only need to take a look at the success of NFL’s Big Data Bowl to understand why.
Touchdown
The competition has been run annually since the 2018-19 season, and has been an unqualified success. The latest (2020-21) competition saw more than 250 entries.
And while the top prize this year was US$25,000, it seems like a pretty good bargain to get 250 teams of data scientists working on a project, amateur or otherwise.
So it’s disappointing to not see more sports teams or organisations adopt this model.
For small-market teams competing against the Dodgers or the Lakers, or organisations involved in sports where revenues might be smaller, this might be a great way to generate research in their areas of interest.
This is also a way to generate a pipeline of future analysts. What better way to find the best available analysts than being able to see what they can do in the same context as the actual job? According to the NFL, Big Data Bowl has already helped 15 participants secure jobs with either NFL clubs or affiliate vendors. Hirings of Big Data Bowl participants are now newsworthy.
Lastly, it must help to bridge the gap between pro sports and its fans. Deployment of advanced data is not going anywhere. But without communicating what the data teaches the teams and players, and where the game is evolving, it will alienate the fans. Making more of it accessible will help for journalists or hardcore fans to understand particular tactics or evolution of the game which will in turn be diffused to the mainstream.
It seems to me that sooner or later someone, whether it be a small team, or a state-sponsored sports institution, would embrace the open source community. I think they would buy themselves a lot of goodwill, learn a lot from the process, and gain an edge from doing so if it’s done right.
Eye-catchers
Speaking of data, if you’re into tennis:


This work by Emilia Ruzicka is a great idea that is well-presented, not to mention very cute


And… presented without comment 🙄


Thanks for reading :). I am trying to stay off of Twitter these days but I do check it about once a week so pls reach out if you have any comments.
If you liked this - please share / subscribe!