
No data? No problem
Or how I learned to stop worrying and love ML models

Hi!
The last few weeks/months have been pretty hectic; I’d been working on a few really exciting projects. I can’t share too much yet, but I did have a few adjacent thoughts. Since this is a data and visualisation blog, let’s start with a few (moving) pictures.
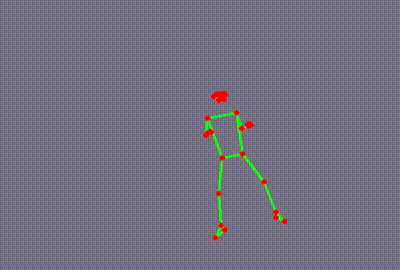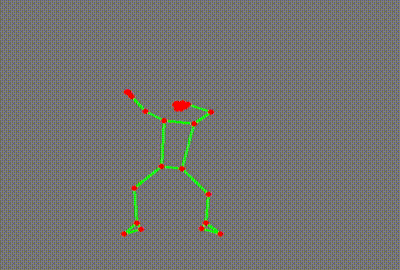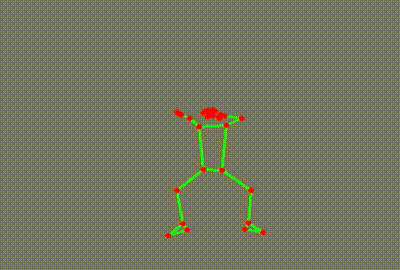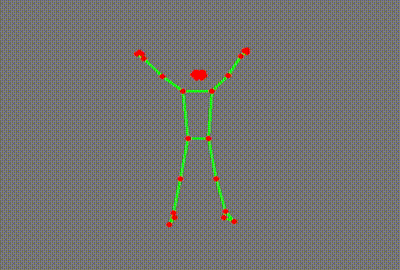
What on earth is this, you ask?
It’s a skeleton extracted from a YouTube video of a ballet dancer. (Extra kudos to you if you spotted it immediately!)
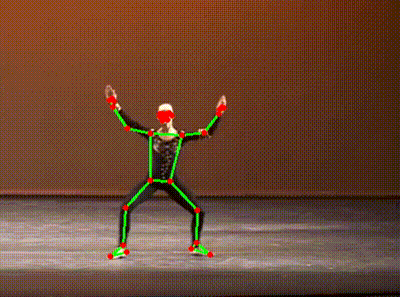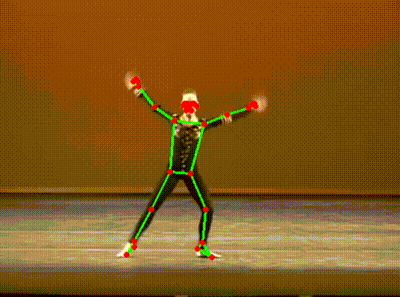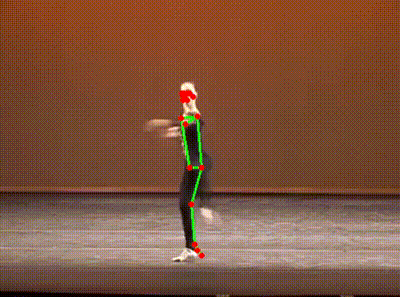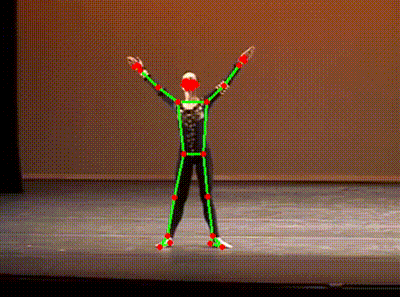
Here is another, capturing a (ahem) slightly less orthodox form of dance.
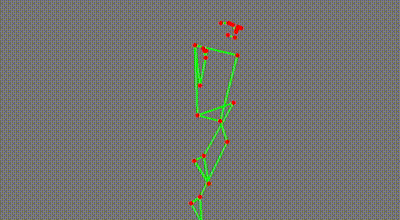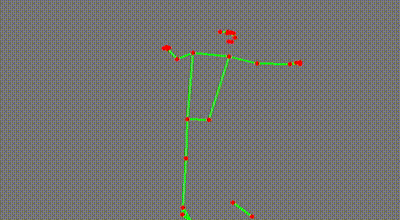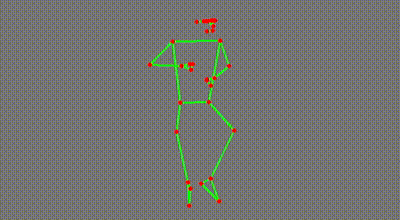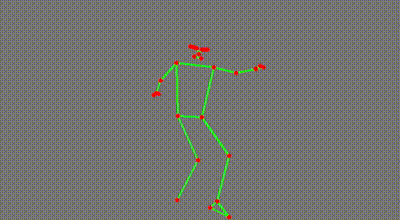
Here is the actual footage with the overlay.

You would probably not be surprised by the fact that these were generated by an AI model. More specifically, they were generated by a “pose estimation” model going through each YouTube video and identifying key points on the person’s body. These points are then superimposed onto the image, lines are drawn where appropriate, and voila - we have our own dancing skeletons.
That’s not all. Maybe I want to copy Serena’s service motion, or learn how to shoot free throws like Steve Nash:

This gives us more than just visuals. Because the model predicts the location of the joints, I can extract from the videos these experts’ body motion.
No, doesn’t mean that I can immediately copy them, especially given how uncoordinated I am at times. But it sure helps me recognise and understand what’s going on. I could even film myself shooting free throws and compare it quantitatively against anyone else’s. It’s really exciting.
But the applicability of this model isn’t what I wanted to focus on.
What did surprise me were these: a) I could pick up a pre-trained, off-the-shelf model to do this for free, and b) generate these in real-time on my MacBook, without a fancy GPU.
In other words, machine learning is more accessible than ever. Literally anyone can stand on the shoulders of giants as well as to extract the shape made by those very shoulders.
Add that to the ever-growig availability of high-quality datasets, the days of data availability being the bottleneck is fast disappearing.
Just to be clear, I am not arguing that we have all the data we need (far from it - as an example, look up things like the gender data gap). I am simply pointing out that there is more data going around than we know how to deal with, and it’s never been easier to generate more.
People can scrape websites (*its legality appears to be still quite uncertain, despite a famous legal victory), download government data, and take advantage of data from data competitions. And now that machine learning models are more accessible than ever, you can generate your own custom data at little to no cost.
The real value, as always, is in identifying what the data can teach us. Pose estimation by itself is a nice gimmick, like extracting the skeleton of the dancers. But applied to a coaching setting, or sports analytics, there’s going to be great deal of value added. It’s the same with language processing, object detection or whatever. These are just tools. But these tools are clearly getting to a stage where they’re more accessible than ever, both in cost, compute required and ease of use (although there’s quite a lot of work still required there imo).
Get out there and take a look at what’s possible. I was amazed at what I found, and you will probably be too.
FYI: I did the above using the MediaPipe library by google. This repo is a good place to start looking around also.
As a PSA - The pandemic burnout is real. For various personal and pandemic reasons I wasn’t at 100%, and I took on probably too much work at once given the circumstances. I was wrong to think that I could just power through it all and not suffer for it. Look after yourselves!
Eye-catchers
Bravo, SCMP
What a portfolio


Don’t be this guy
When someone else’s cool DataViz is used to imbue meaning to your word salad.


@canzhiye said it best:

Lessons to viz by
You can do so much with so little.

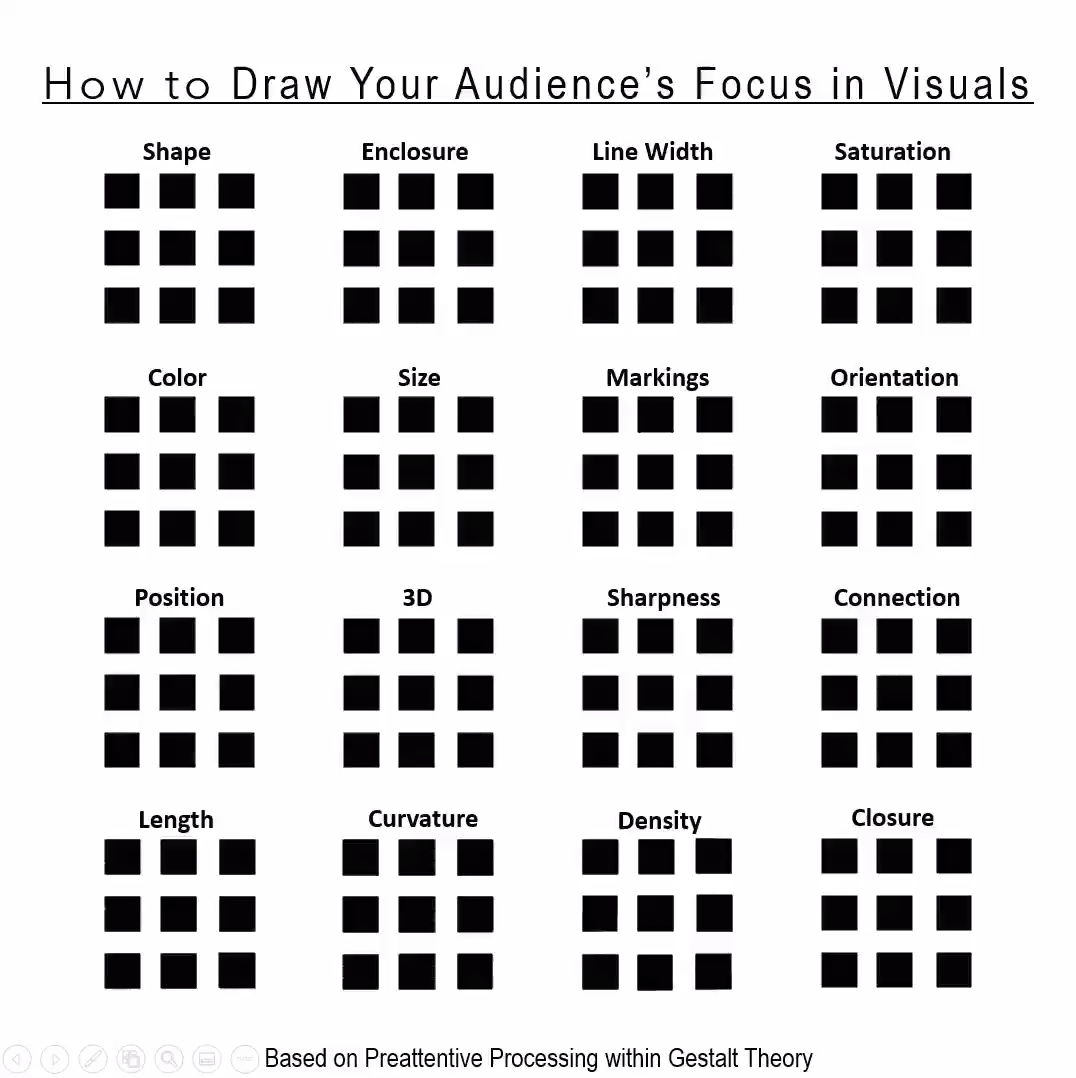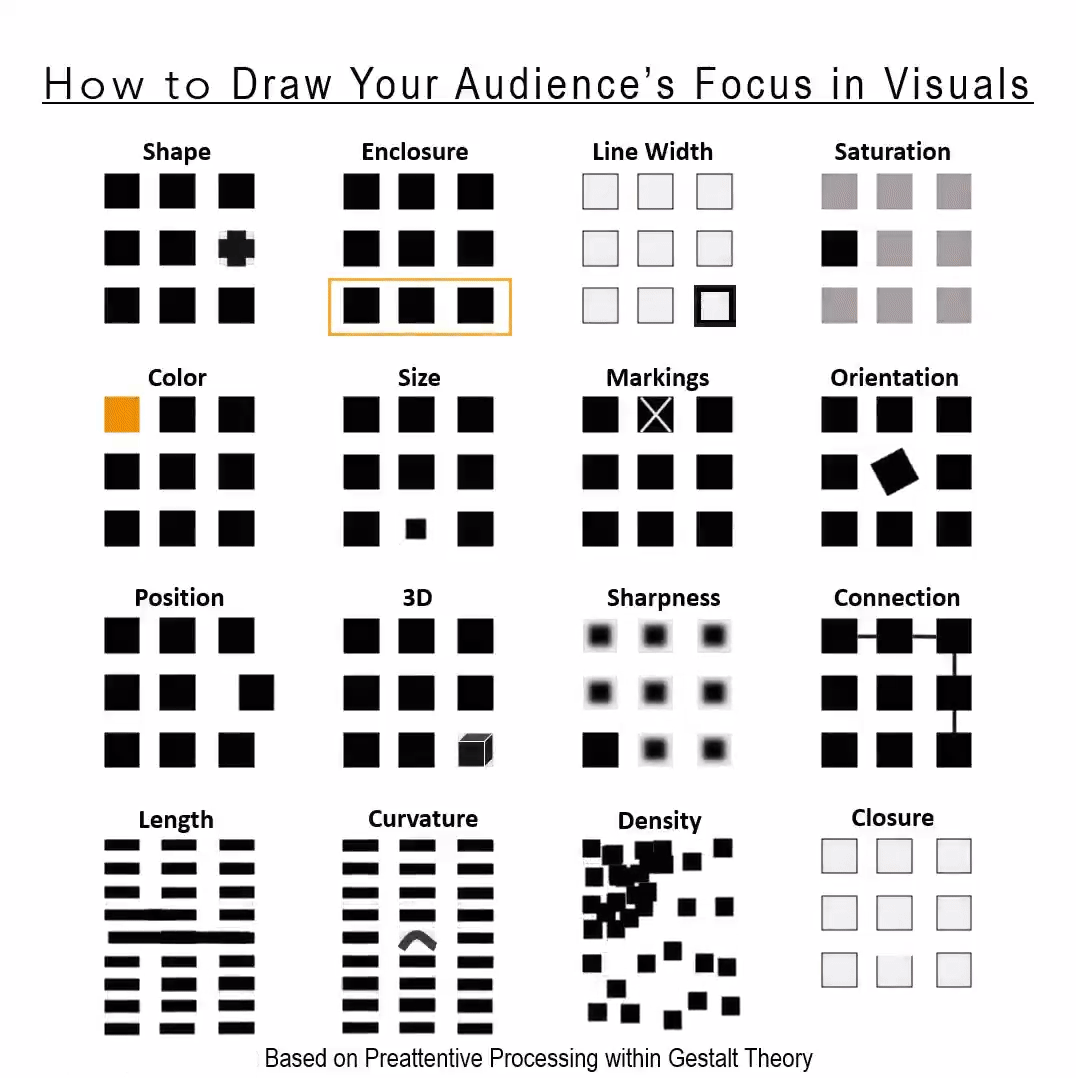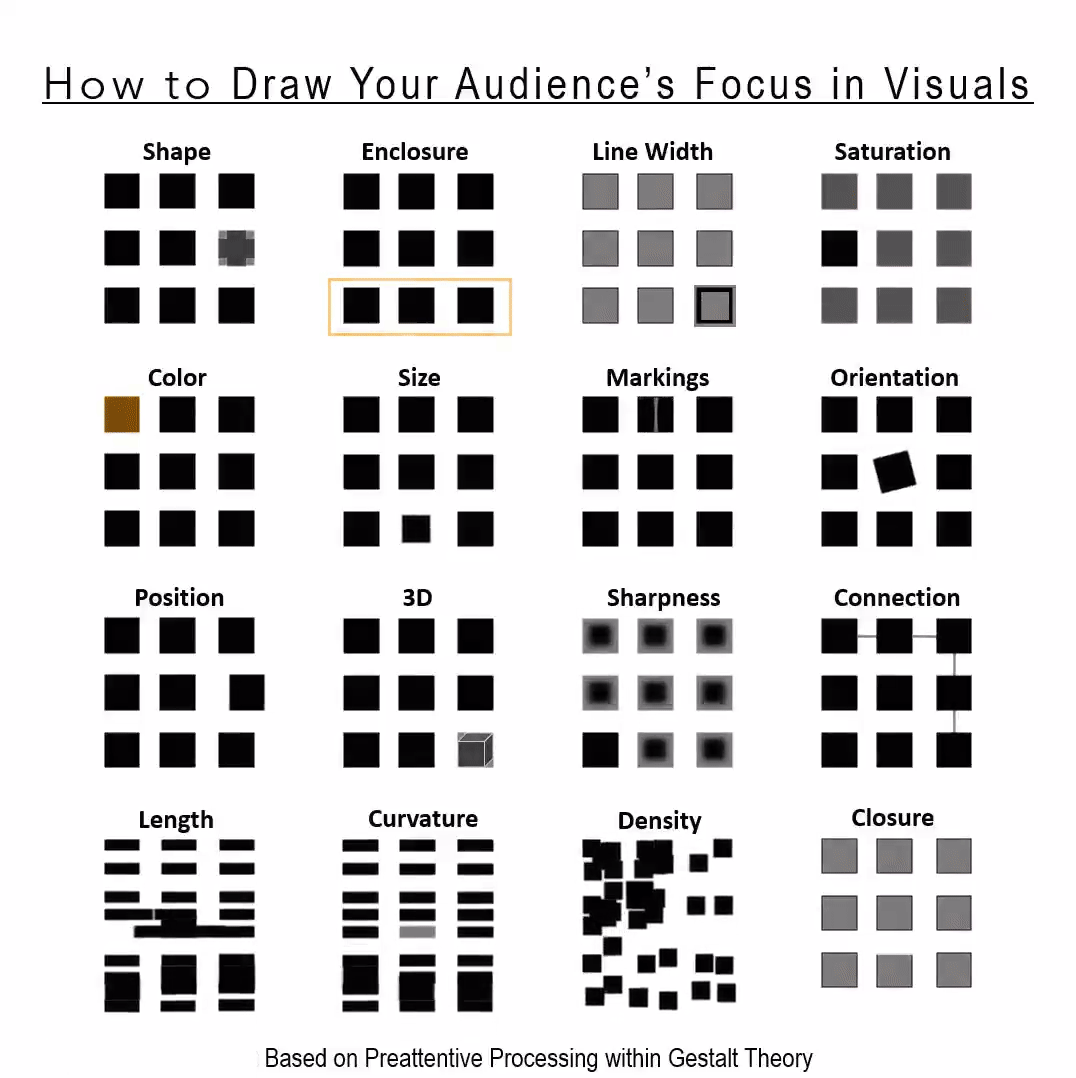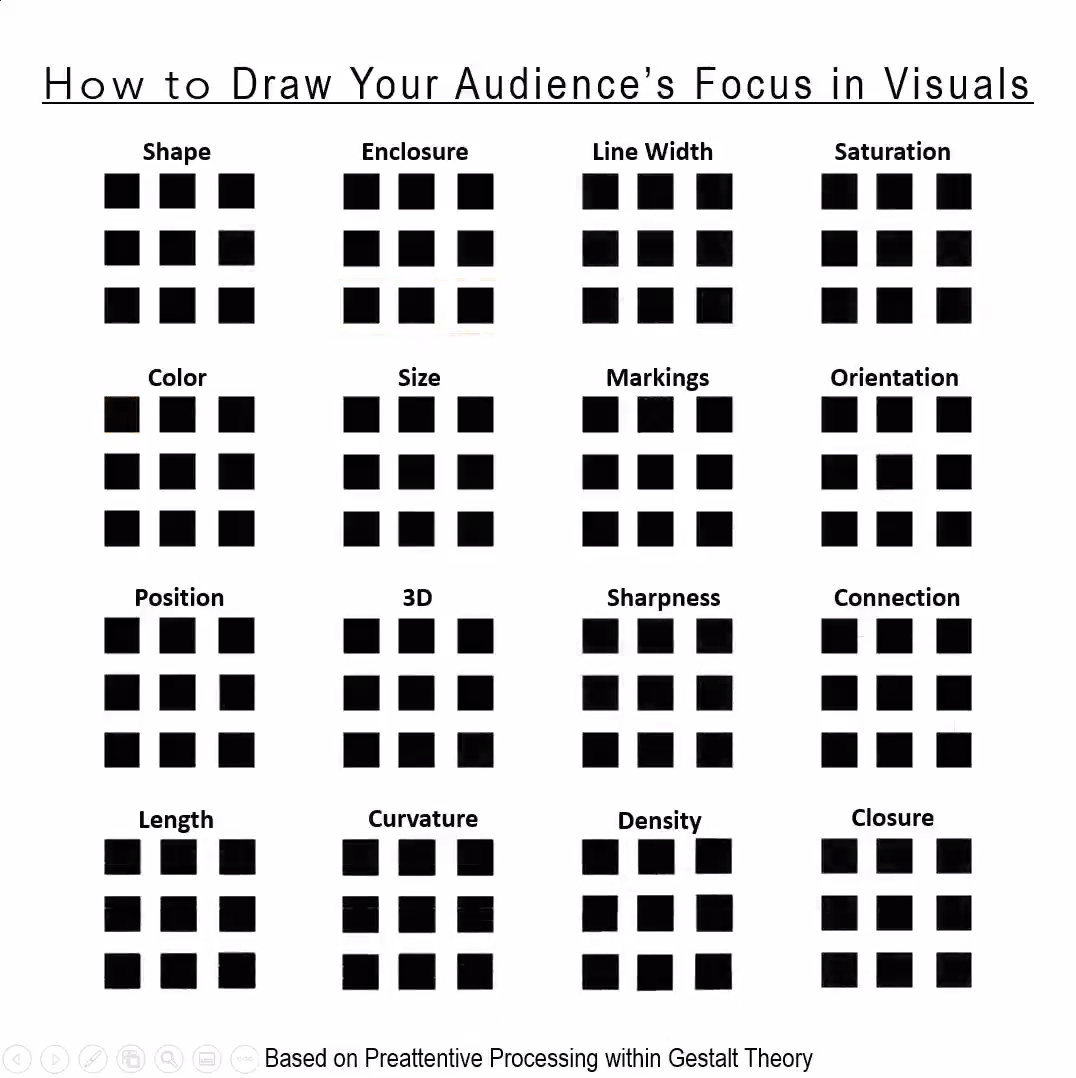
If you liked the post, you can share it here:
And please remember to subscribe if you haven’t: